
Introduction
In the world of artificial intelligence (AI) and automation, language models such as OpenAI’s LLM (Language Model) have proven to be powerful tools. Tokens are a crucial component of these models, playing a significant role in text processing and generation. In this blog post, we will delve into the workings of tokens in LLMs, explain the varying lengths of tokens, explore how tokens are billed by OpenAI, and provide examples of sentences with different token counts to illustrate the concept.
The Functionality of Tokens in LLMs: Tokens serve as fundamental building blocks in LLMs for composing text. A token can represent a single character, a word, or even a longer text unit such as a paragraph or heading. When processing text, an LLM breaks down the input into a sequence of tokens, enabling it to analyze and generate text more efficiently. By segmenting language into smaller units, the text becomes more accessible to the model, facilitating faster computations.
Token Length Variability
The length of tokens in LLMs can vary depending on the model configuration. Generally, tokens have a maximum length, often ranging from 16 to 512 characters. It is important to note that tokens do not always correspond to individual words. In cases of compound words or languages other than English, a token might represent a portion of a word. For example, the English word “unhappiness” could be represented by two tokens, “un” and “happiness.”
The length of tokens is influenced by factors such as language, model settings, and specific application requirements. Longer maximum token lengths can capture complex sentences or text passages more accurately, while shorter token lengths can enhance processing speed. Determining the appropriate token length involves finding a balance between precision and efficiency.
Token Billing by OpenAI
OpenAI employs tokens as a unit for billing in LLM usage. Each token generated or retrieved by a user is taken into account for billing purposes. The number of tokens impacts the costs and resource utilization. Longer text inputs or generated outputs consequently involve more tokens, which can affect pricing and execution time.
Considering token count is crucial when utilizing LLMs to manage costs effectively. Optimizing text inputs and employing precise and concise formulations can reduce the number of tokens used, thereby controlling expenses.
Examples of Sentences with Different Token Counts
To better grasp the concept of tokens, let’s consider some examples of sentences with varying token counts:

We can see that even short exclamations can already consist of two tokens.

The space in front of each word is part of that words token. This is useful knowledge for influencing the LLMs behavior.
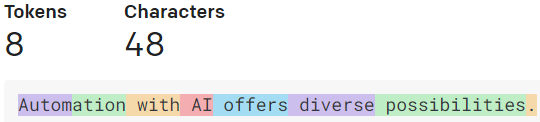
Notice how the length of a word does not directly correlate with the amount of tokens.


Interestingly enough this example shows us, that even longer repetitions of the same symbol can become less tokens. There really is no correlation between length and token-usage.
These examples illustrate that even short sentences consist of multiple tokens when considering spaces and punctuation marks. Overall we can still use 4 characters per token as a rough estimate, but it can vary widely and per language.
Conclusion: Tokens play a crucial role in LLMs, enabling efficient text processing and generation. Their length can vary depending on model configuration and the language being processed. OpenAI bills LLM usage based on tokens, which determines the costs and resource utilization. It is important to consider token count to manage expenses effectively. By understanding the functionality and significance of tokens, we can harness the possibilities and potentials of automation with AI more effectively.
If you want to learn more about LLM usage or require assistance in implementing automated solutions for your business, I am here to help. Contact me at contact@pytotyp.com to leverage the benefits of automation with AI and optimize your workflows. Let us collaborate to shape the future of automation together!
Leave a Reply